
I decided to study recent advances in Artificial Intelligence (AI) for three reasons:
AI has transitioned from the lab to companies and organizations. Powerful computers, abundant data and wide communication networks favored an explosion of applications that are already part of our daily lives.
It's a field that provokes mixed feelings. We expect advances to be up to the sci-fi vision that we imagine, but when they come true, we are invaded by apocalyptic visions of robotic domination.
It's not the first time there's been high expectations. For as long as I can remember, the expert opinion is that in 20 years there will be a general artificial intelligence that equals or surpasses the human being in all fields. That's what they said in the '80s and that's what they say today.
To find out for myself how far things progressed I enrolled in a couple of courses, one on AI in general and one on machine learning (ML), the branch of AI that studies techniques for discovering patterns and relationships in the data that let us make predictions or make decisions. I discovered that this branch of AI is behind this decade’s extraordinary achievements.
The efforts to take advanced courses on a technical topic, on platforms and with programming languages that did not exist when I stopped making systems very early in my career, were surpassed by my astonishment at the power of ML tools.

One of the exercises of the course was to develop a program that, from the texts of 50 thousand viewers comments to movies, each labeled as positive or negative, would predict the positive or negative character of another 50 thousand unlabeled comments. The exercise would be graded with the percentage of accuracy.
My enthusiasm was enormous to see that the data was on the internet, that there were the tools to collect it and that after some effort I was able to do a program that did the exercise in just over an hour. Everything at no cost, from home and with a laptop. That's when the magnitude of these advances became clear to me, a company could analyze hundreds of thousands or millions of reviews in minutes and have a real-time picture of the public's opinion of a movie, without reading a single comment.
Realizing that, if you have the data, ML can be easily applied in any activity where structured data is analyzed to draw a conclusion, I was amazed at the magnitude of the impact these tools will have on the economy, government activity and our daily lives. That's what this is all about, this is the reason of the frequent news, the rush to develop apps and fears about the implications of their use.
ML algorithms carry out something that humans continually do: to try to make sense of the information we receive from the environment in order to make decisions. Throughout our lives the brain learns to automatically fill in the gaps in the information we receive and to find patterns that can be used to draw conclusions.
For example, if we study the figures
below, it won't take us long to fill in the gaps and have a complete picture.
This process is called inference, we draw conclusions from the information we
have.
Dogs and cats by macrovector_official
Our capacity for inference is powerful but limited, larger volumes of data to handle and more complex patterns to be detected makes thing more difficult for us, until there comes a point where we can no longer do them.
In contrast, today's ML techniques and algorithms can make inferences about unlimited amounts of data at incredible speeds, only limited by the capacity of computer equipment, so they are able to find patterns that humans simply can't discover or, at best, would take too long to do so.
These techniques, almost all of them developed by researchers in the 80s and 90s during the so-called AI winter, evolved and were implemented in this century thanks to the availability of computers, data and networks, resulting in an AI spring with the potential to change the history of humanity. (Read our article about the history of this field).
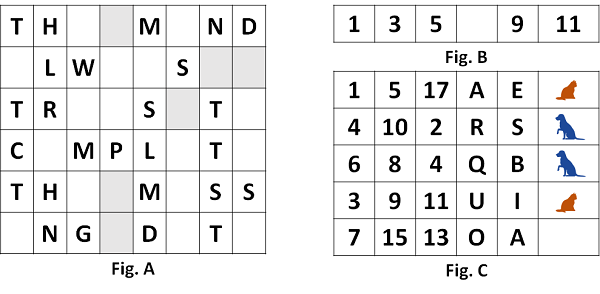
These are the types of ML and techniques that can be used in each type, depending on the nature of the problem to be solved:
Supervised Learning. From selected data (attributes) from a large number of examples, each labeled with a category or value, parameters are found to predict the value or category. It is divided into two types:
Regression - When the category to predict is a number (as in figure B). Techniques: linear regression, crest regression, Bayesian regression.
Classification - When the category to predict is not numerical (as in figure C). Techniques: logistic regression, vector support machines, Bayesian classifier, decision trees, k-neighbors and artificial neural networks. (read our article on deep networks)
Unsupervised Learning. Only from the attributes of the examples, unlabeled
with a category or value, patterns are found to group the examples, evaluate
the degree of similarity between them, and make predictions (as in Figure A, or
C without dogs and cats). Techniques: Clustering, Association Rules, Factorization
Matrix, Sequential Models.
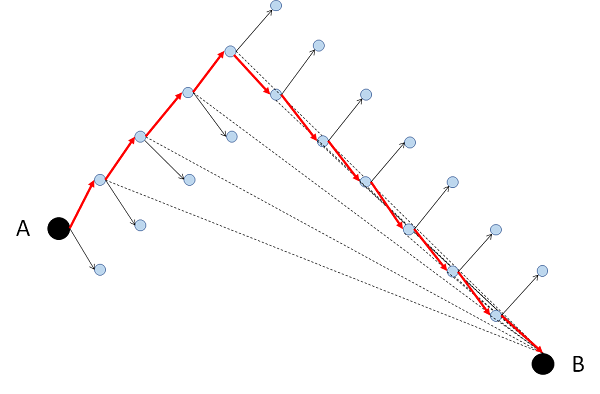
Reinforcement Learning. It's a combination of the two above. It seeks to achieve a goal with a sequence of steps, in which there are several alternative courses of action. At the beginning of each step the alternatives are evaluated, one is chosen, and you see how closer or farther from the goal it took us. The alternative used is then classified according to its contribution to the objective and this information is used in the following steps. It's a trial-and-error process.
A very simple example is shown in the figure below. The goal is to go from point A to point B and at each step we can go up or down. In step 1, as there is no information, we randomly choose to go above. After moving forward, we can see that we approach point B, so going up is classified as positive. In the next three steps we choose to go up because it is better than going down, which has no classification. However, after step 4 we can see that we move away from point B, so going up is now classified as negative and we choose to go down. After step 5 we see that we are closer to point B, so going down is classified as positive. In the next steps we continue to approach, so the classifications don’t change (up negative and down positive) and we continue to choose to go down until we reach point B.
ML algorithms have managed to overcome the performance that a human being can achieve in many activities that involve data analysis and make possible inferences that were previously not feasible or practical to perform. This allows the development of new products and services that will help improve people's lives, but also promotes the automation of activities that were previously thought to be unable to perform a machine.
Civil society and government must take steps to make the benefits of implementing these technologies outweigh the negative effects. In that effort, being informed is the first step.
Did you enjoy this post? Read another of our posts here.


